Starting this blog with questions:
- How do you deploy a highly available fileserver in Azure?
- Do you count on the SLA (99.9%) of Azure when using premium storage, so doing a single fileserver?
- How does it perform?
In this post I’m diving in on Storage Spaces Direct in Azure, giving a few guidelines but also some real-world performance results.
Got quite a few charts and tables in there, get an extra coffee. Hang on tight, here we go!
Size matters
Not only the types of disks you choose for the solution is important, the VM size is key in this.
Each Premium Storage-supported VM size has scale limits and performance specifications for IOPS, bandwidth, and the number of disks that can be attached per VM. When you use premium storage disks with VMs, make sure that there is sufficient IOPS and bandwidth on your VM to drive disk traffic.
For Example:

So even if you combine 10 premium storage disks, it does not mean your VM will actually handle the IO because of VM limitations.
And to be frank, many times you end up with a VM size that is way oversized on the CPU and Memory side if you only use it as fileserver, which means $$$.
Tests
Below I show a few tests that have been done. All tests are performed using diskspd.exe which you can find here:
Every test is using the following parameters:
- 8 outstanding IOs,
- ‘-Sh’ parameter (Disable both software caching and hardware write caching)
Running tests with threads from 1 to 18. Results have shown that we are hitting limits using between 8-12 threads.
Charts and tables are shown for 100% read and 100% write tests.
Test case – Single Server
Disks: 1x OS Disk
4x P30 disk (5000 IOPS – 200 MB/s)
VM Size: Standard_D32s_v3
Volume: Storage Spaces Simple – 4 columns
As Storage Spaces Direct is depended on Ethernet for storage replication I thought it would be fair so see what a single server with locally coupled disks could do. After this we compare it with a S2D cluster.
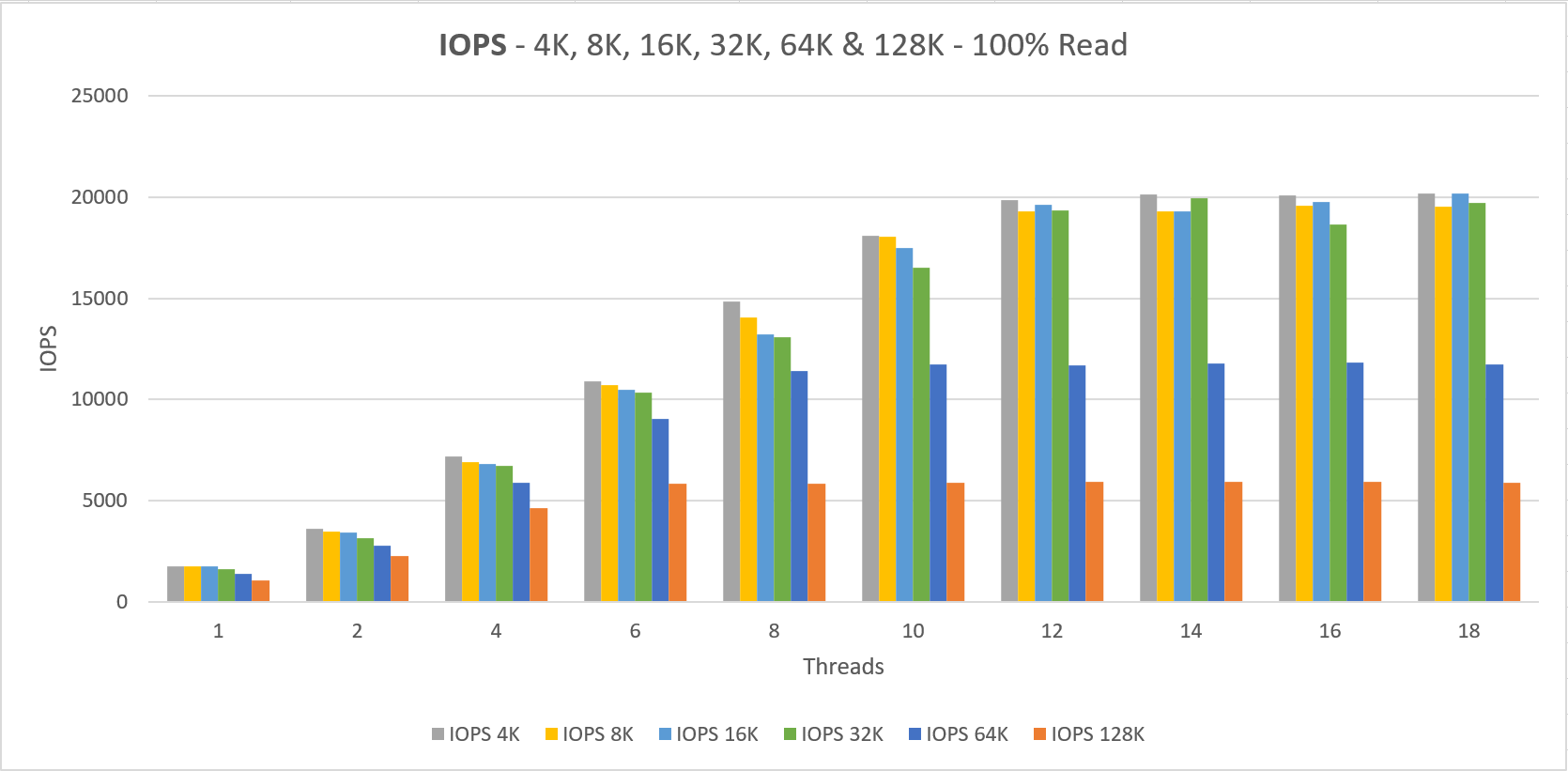
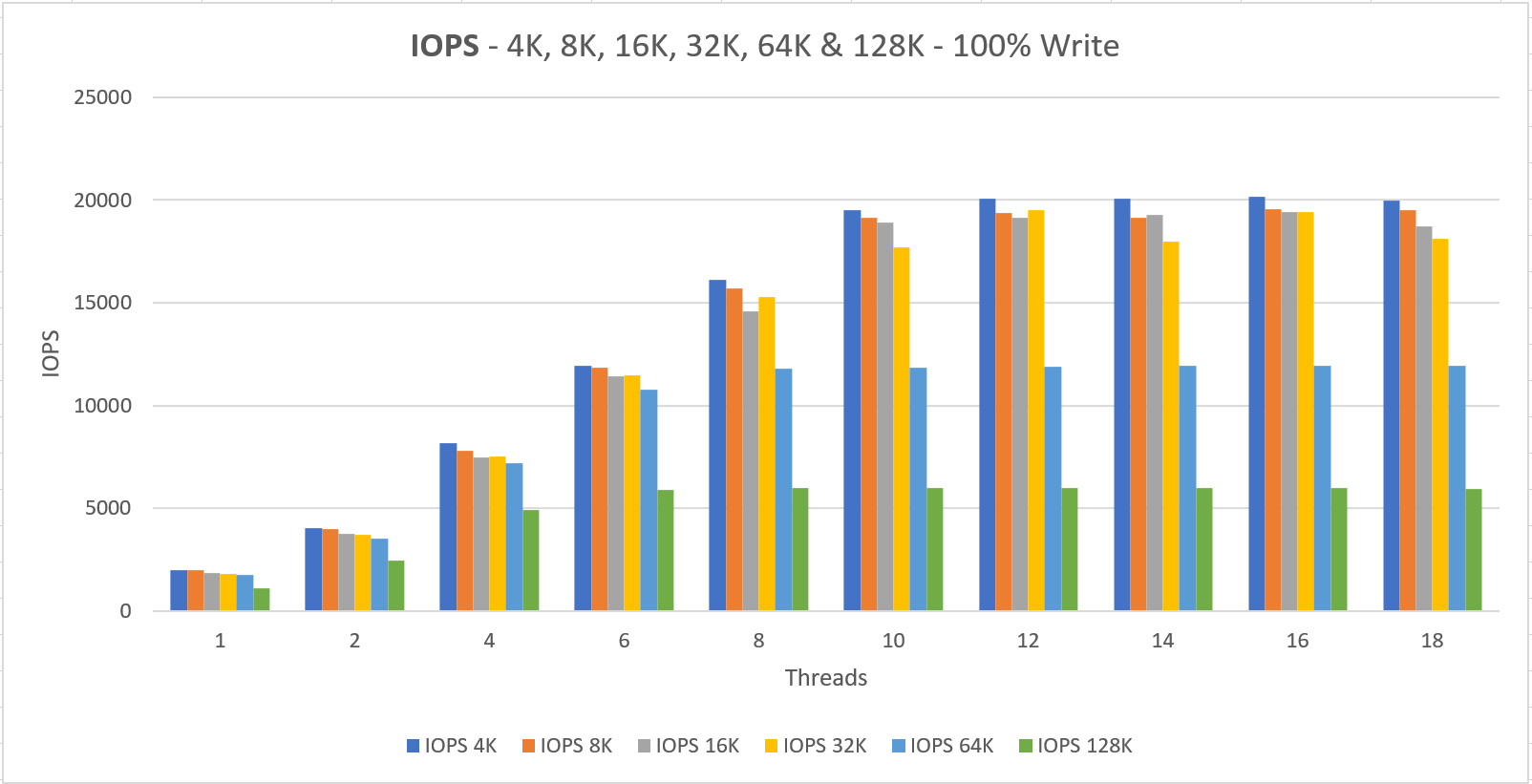

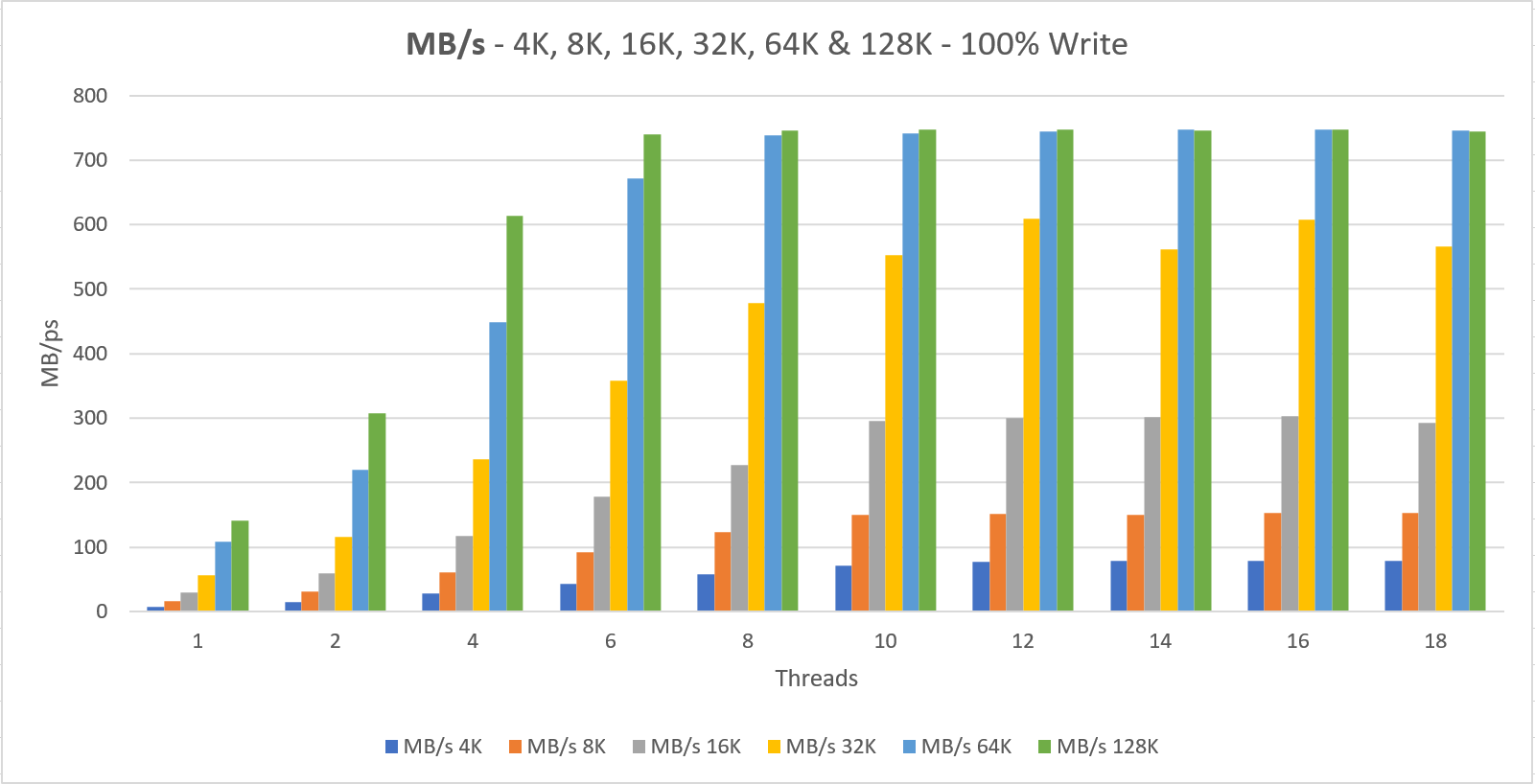

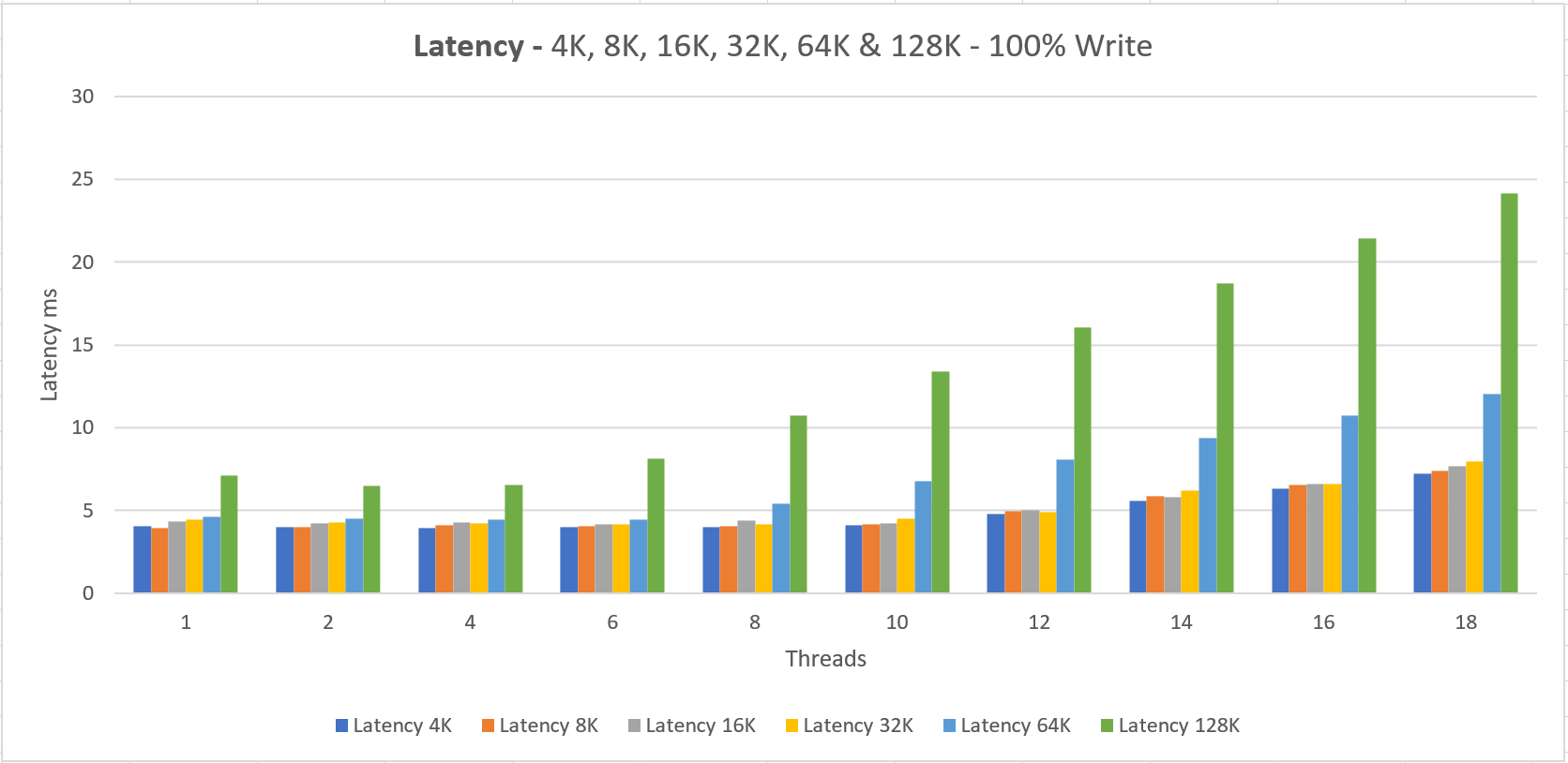
The server has 4x a P30 disk attached (5000 IOPS – 200 MB/s) which totals up to a 20,000 IOPS and/or 800 MB/s limit.
The VM Size can do 51,200 IOPS and 768 MB/s and as the charts show we’re hitting that MB/s limit as we should be able to go to 800 MB/s if the VM size was adequate. (yes, this was on purpose 😉 )
Two things to notice here;
1. We never getting the documented performance when using a small number of threads that do IO
In fact, when we’re doing 4K IO with a single thread we get a staggering 1985 IOPS and 7.76 MB/s
2. The minimum latency lays around 4 ms for read and write operations
Test case – Storage Spaces Direct
3-Node – Windows Server 2019 – Storage Spaces Direct Cluster
Disks per node:
1x OS Disk
4x P30 disk (5000 IOPS – 200 MB/s)
VM Size: Standard L16s
Volume: 3-way mirror – 4 columns
Network Acceleration Disabled (not available on Storage optimized VMs, v1)
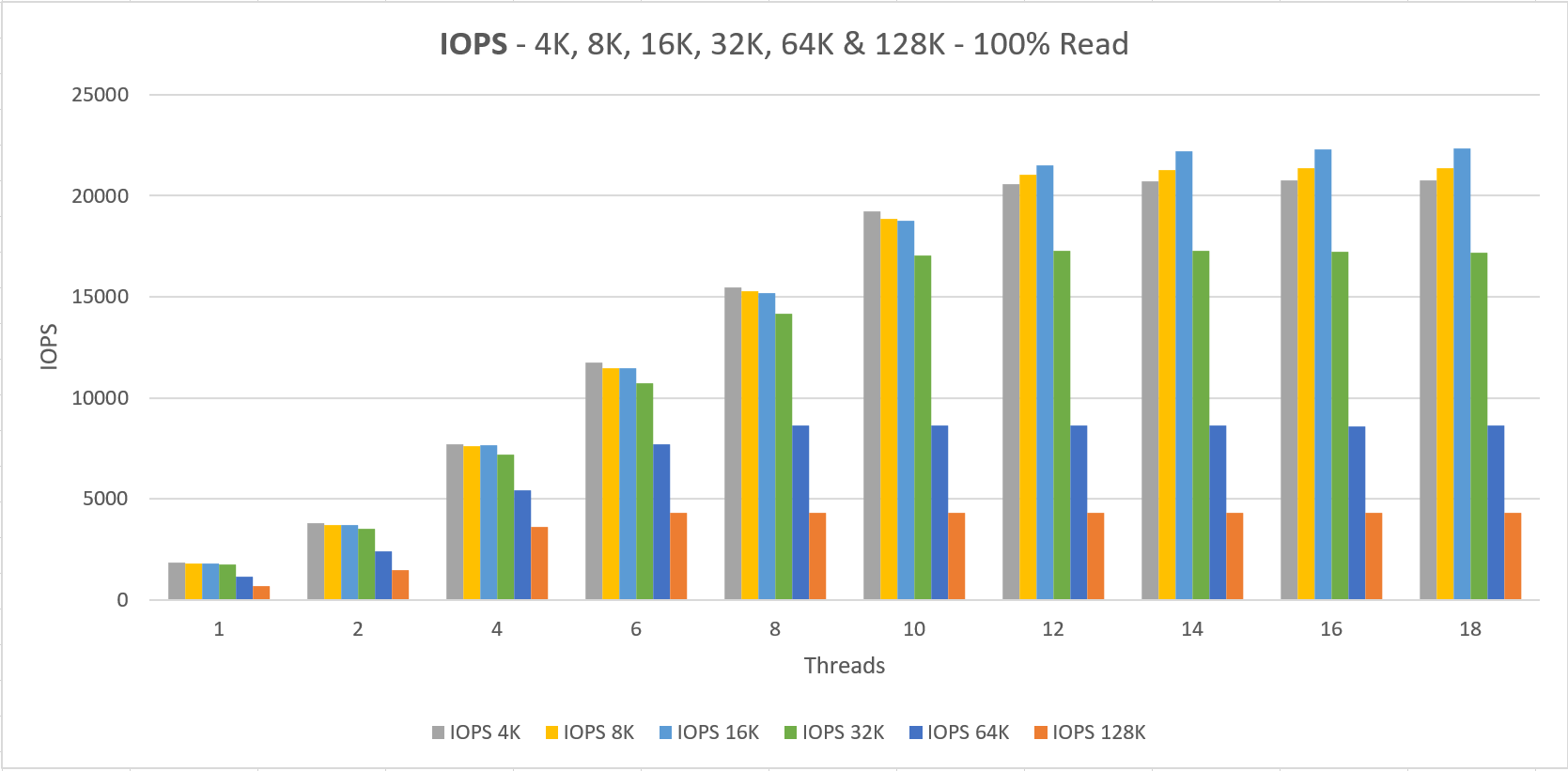
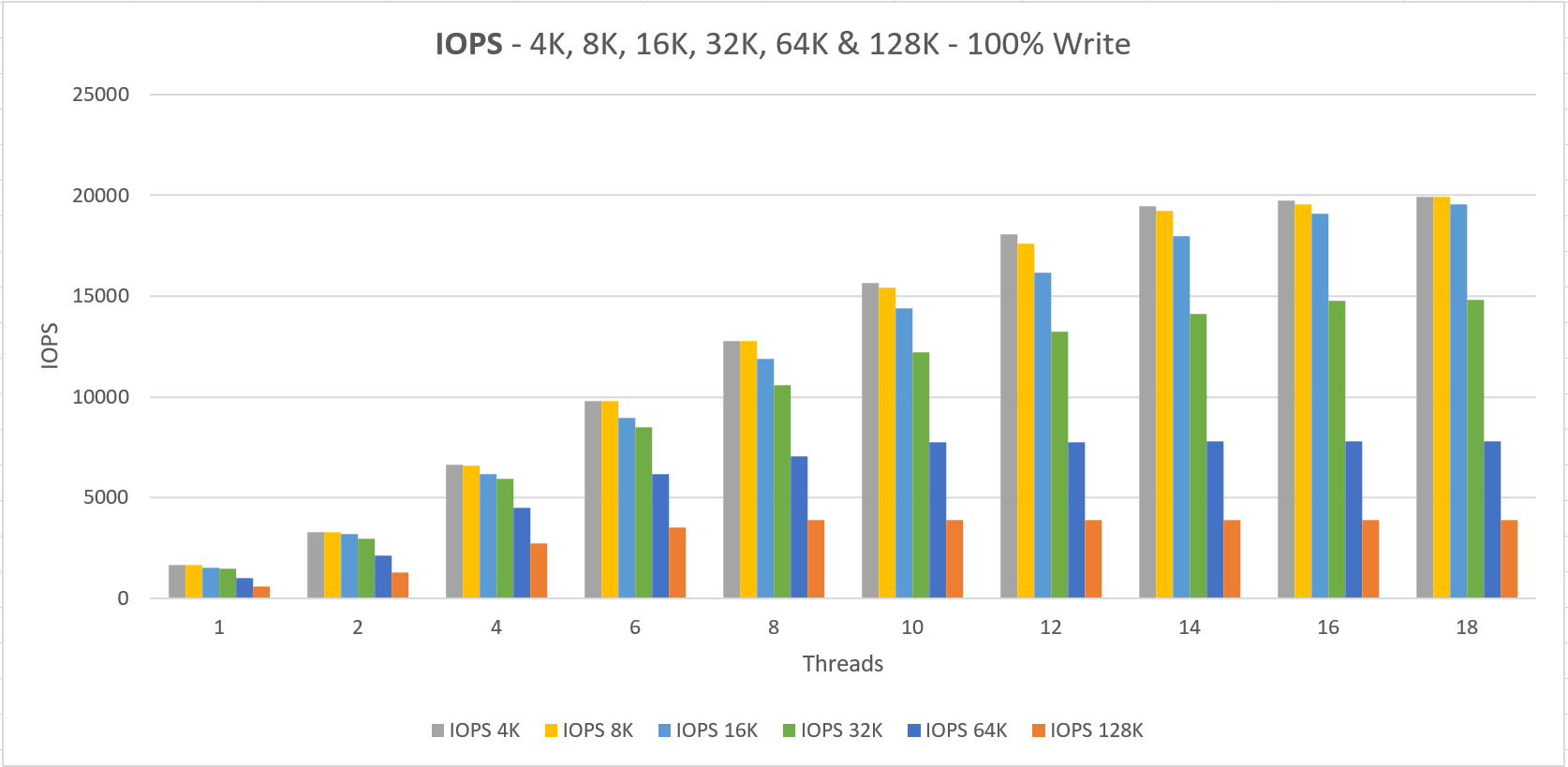
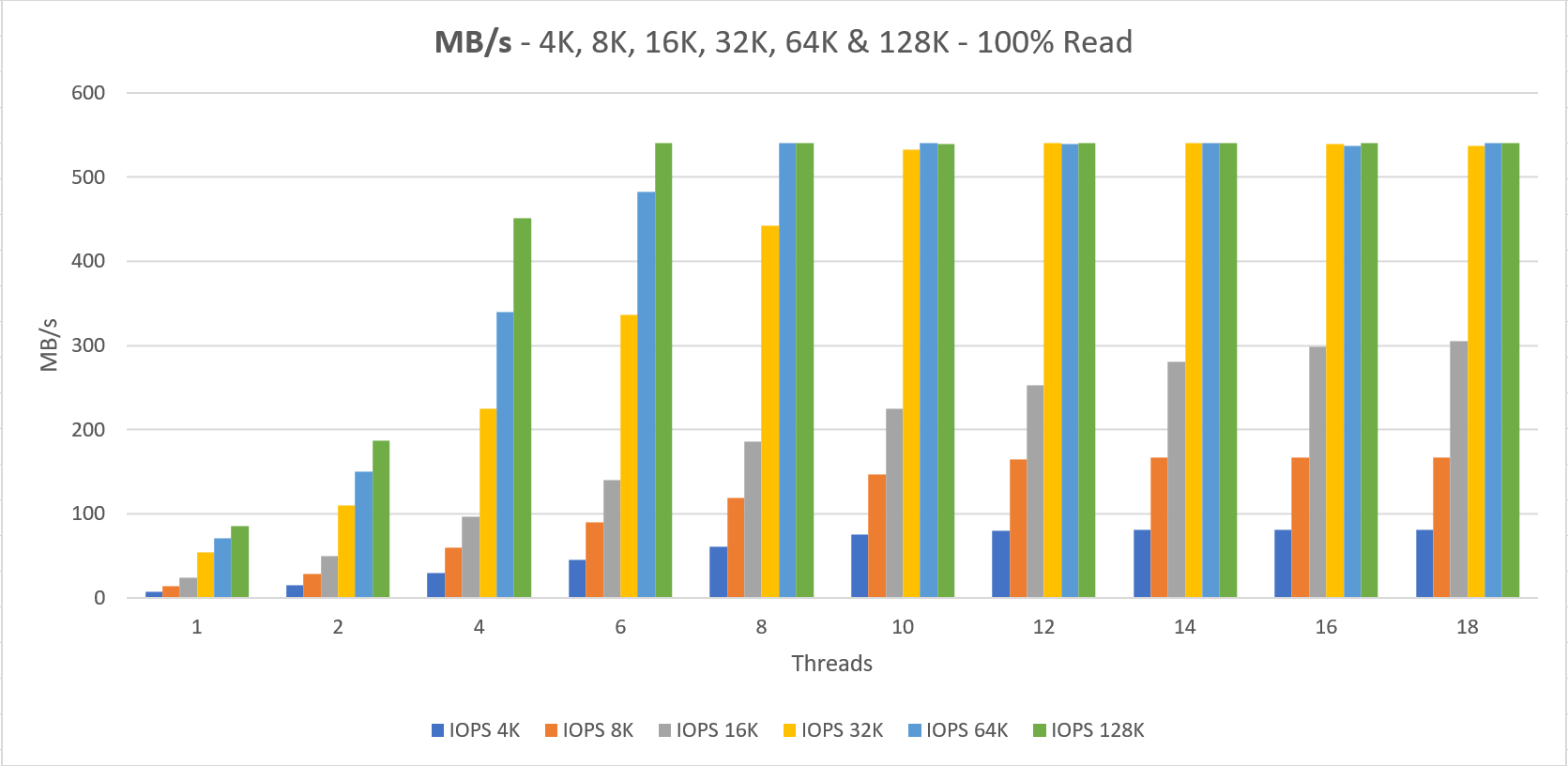
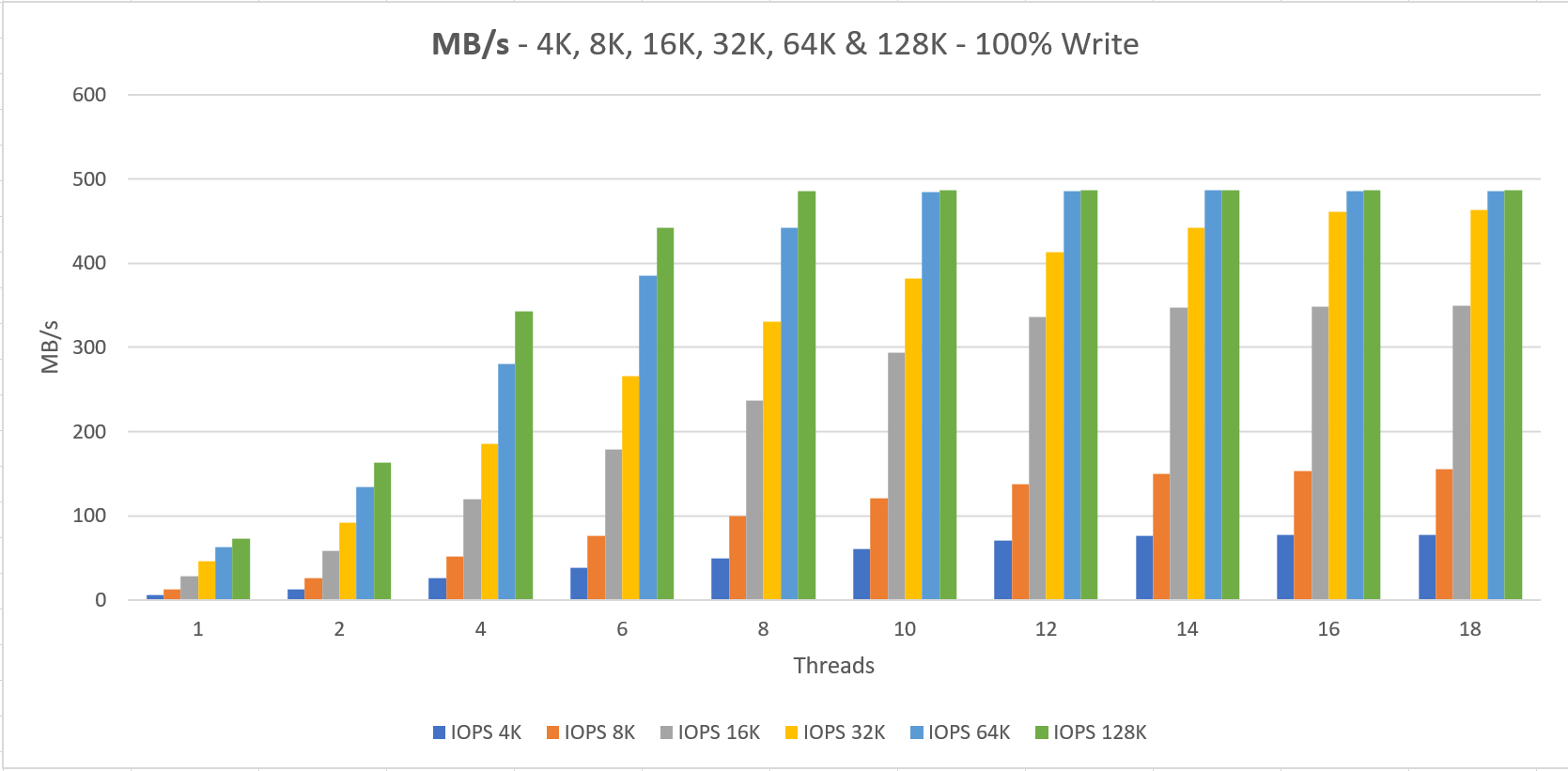

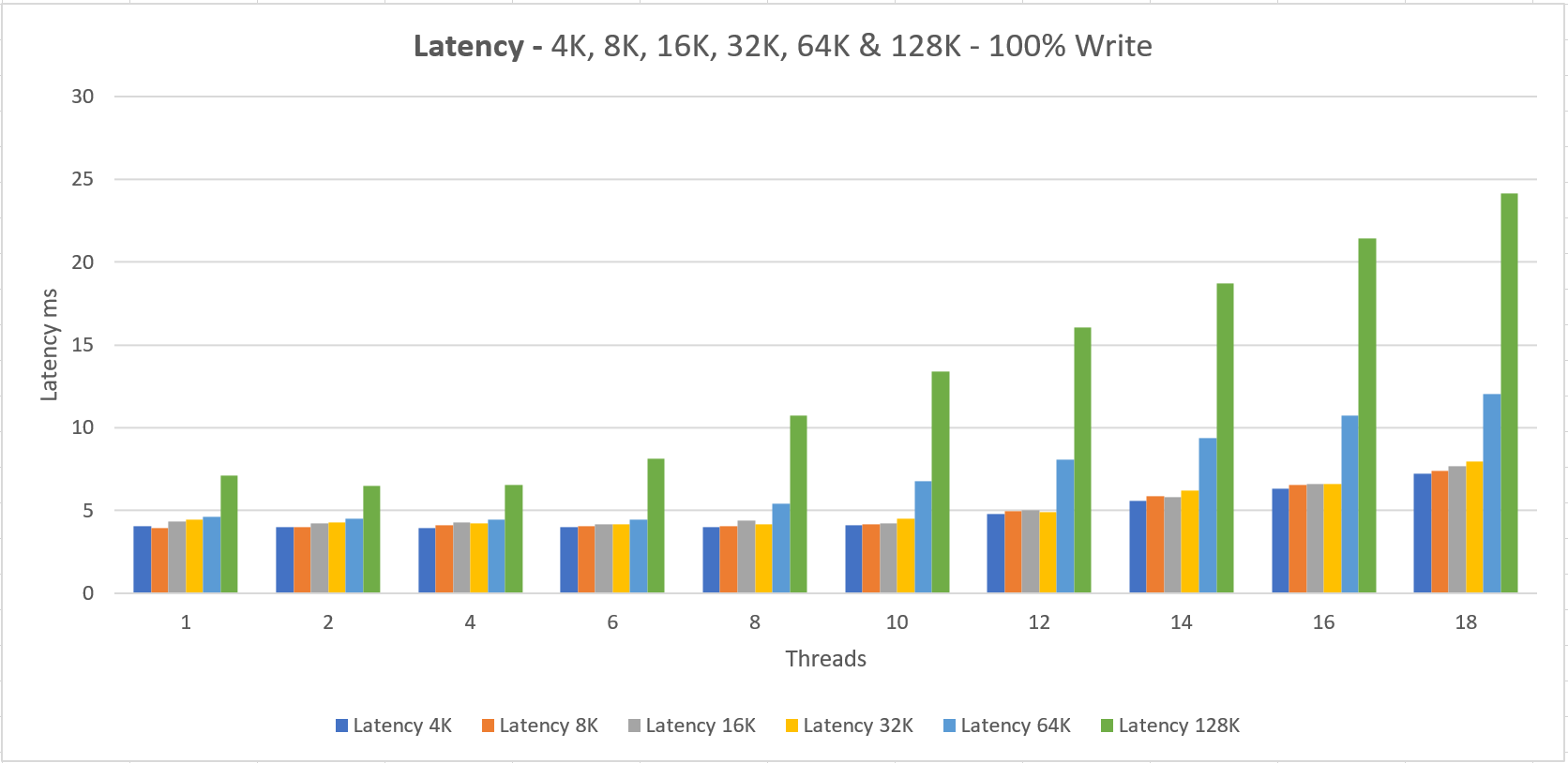
The VM size “Standard L16s” is capable of doing 20.000 IOPS which we are able to reach with 4x P30, which also sums up to a 20.000 IOPS limit on the storage side.
Two things to notice here;
1. We never getting the documented performance when using a small number of threads that do IO
2. The minimum latency lays around 4 ms for read and write operations
Comparison
The focused reader should have noticed that we had the same things to notice with a single server and a Storage Spaces Direct cluster. I did the below comparison on the ’12 threads test’ as this is the test that gets the most out of the storage.
“SS” = Single Server
“S2D” = Storage Spaces Direct
When the result is green, S2D performs better:
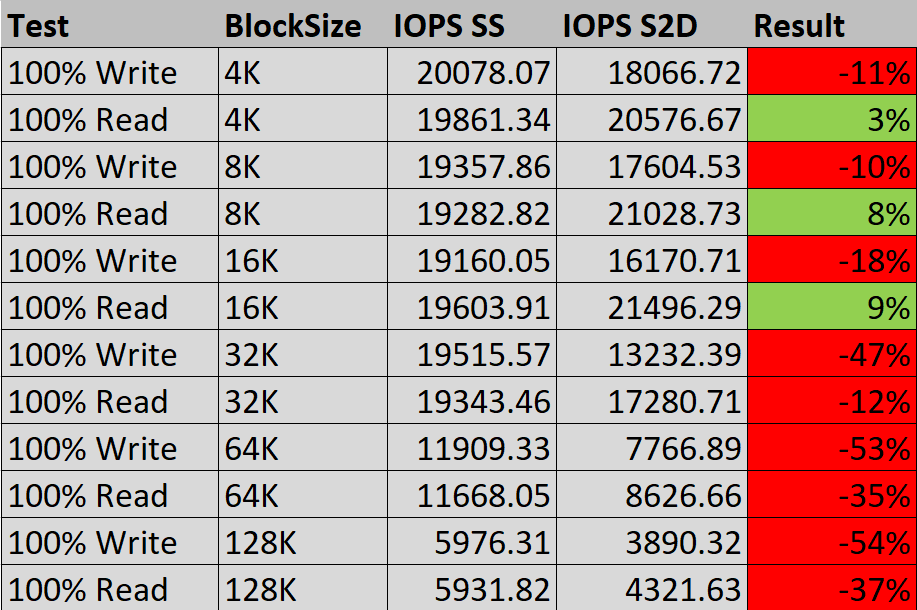
Doing smaller IO, the results are not that far apart.
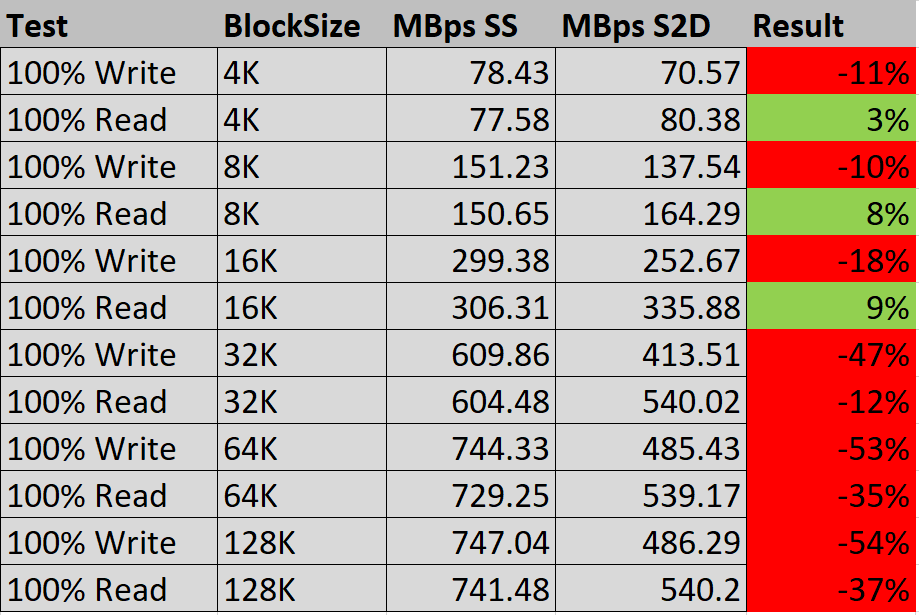
Same goes for the MBps.

The latency table contains the most valuable information we’re looking for, it shows the latency in milliseconds is not far apart. Even though reads and writes have to come from another (remote) node, the latency difference is very small. AND I have not enabled Network Acceleration. This shows that the latency we see in the tests are coming from the storage and not the network side.
It’s all about latency
If you paid close attention on the comparison tables you’d see that the same tests are either red or green, it all correlates.
I would like to take a quote from a blog by Microsoft released in 2016, as I could not have explain it better:
For example, the Premium Disk P30 disk limit is 5000 IOPS and 200MB/s. This is the upper limit you can get for async IOs if you push enough IOs. For single thread sync IO, you will never get to this limit unless the sync IO uses multiple processes/threads that keep the outstanding IO or disk queue high. Most of the existing docs simply suggest adding more disks to improve the performance and we frequently see customers adding more disks; however, in this kind of sync IO situation, additional disks will not help. The truth is, for single thread sync IO, the max IO you can get is only related to the disk latency.
To further demonstrate this, think about a situation where you have a team to help you send packages to your remote office. Each time you ask a team member to take a package from the main office, drive to the remote office, return to the main office, and then ask the second team member to do the same. If the round trip time is 10 minutes, then no matter how many employees you have, you can only send six packages per hour. This is how sync IO works.
Therefore, to calculate the IOPs for Premium disk, we will simply need the disk latency. For Azure Premium disk the latency is around 2ms. In 1 second (1000 ms), you can get 1000ms/(2ms/IO) = 500 IOs. Since the limitation is on disk latency, you cannot improve this even if you add additional P30s. We see customers wasting money on the additional storage in hopes that there will be better performance on sync IO, but unfortunately it will not.
Are we using Sync IO with Storage Spaces Direct? Definitely! We need to know if the write IO is actually written so we are waiting for that acknowledgement.
Fun test
Just to show the latency difference , I will compare the Azure P30 disk with my Surface Book 2 SSD (Samsung MZ FLW2562M0Q):

That’s quite a difference…
Conclusion
No matter how many disks you add to your server or cluster, the only way to scale performance from our side is more threads. With more threads we can get the maximum performance out of the disks. With more disks, more threads are needed. Microsoft is hopefully working on things on their side to reduce latency which will benefit us.
Yes, Azure is still cool and rocking but if you want real storage performance with low latency than Azure could not be for you.
Unusable? No. I have heard customers who are running File Servers and User Profile Disks on a S2D cluster in Azure without notable issues.
Curious about your experiences! Leave a comment!
—
Thank you for reading my blog.
If you have any questions or feedback, leave a comment or drop me an email.
Darryl van der Peijl
http://www.twitter.com/DarrylvdPeijl



Hi Darryl,
Great info as usual, but your example picture says:
2000 IOPS
800 MB/s
Should be:
20000 IOPS
800 MB/s
Thanks again Alain, fixed 😉
Note that while the L-series is described as “Storage optimized” this is specifically with respect to the use of the large temporary disk rather than durable data disks hosted in Azure Storage. Unlike other Premium-Storage capable VMs the L-series does not provide a local cache, which limits the upper IOPS limit for durable data disks. The L-series is intended for NoSQL stores, such as Apache Cassandra and MongoDB in which data can be stored on the temporary disk but made durable through the creation of multiple replicas stored on other VMs in the NoSQL cluster.
Thanks for this info Neil!
For your SOFS nodes in Azure, are you using host caching on your VMs with the Premium SSD’s?
Hi Bao,
Not sure anymore, I used the default settings.
Hi Darryl!
Thank you for this detailed post. We currently have a S2D setup on Azure with 2x DS1 v2 and 2x P20 each, but I’m disappointed by the performance. In order to improve performance and not break the bank, what would be the most obvious (or first) thing to change in your opinion?
Thanks!
Joerg.
Hi Joerg,
The disks you are using have high latency. In the meantime Microsoft has brought out new disks with very low latency, see: https://azure.microsoft.com/en-us/blog/azure-ultra-disk-storage-microsoft-s-service-for-your-most-i-o-demanding-workloads/
I have not tested this yet, not sure about costs either.
If you have additional questions, shoot them through the contact form!
Hi Darryl,
I have developed the S2D solution (two-node) for my company as they wanted to migrate to Azure and get rid of on-premises. The on-premises file servers were stand alone. But, in Azure they have HA. This was a cool feature and everybody like it until latency came into picture. I am using E32s_v3 series VMs as cluster nodes. I read your article. I would like you guidance on the infrastructure that I have. I have attached 9 P60 disks (6 minimum) per node. We have 5 two-node clusters in Azure so far. If we need more threads, how do I achieve it? Do I have to bump my VM size.
Thanks,
Mahindra
Hi Mahindra,
Threads is not something that can be changed form VM side, but has to come from the application side.
The only way of speeding up things is reducing latency. Microsoft has released ‘Ultra’ disks which have very low latency, not tested them myself.
Instead of using S2D in Azure, you could also look at Azure Shared Disks, not yet tested myself either.
Thanks for your quick response. I will have to do my research on the ultra disks. Your article helped me gain some insights into S2D that need major attention.
Is there any formula to calculate the IOPS we can get from Storage Space Direct with physical servers. We have 16 node Cluster with HPE ProLiant DL385 Gen10 Plus v2 8SFF, 2 X AMD EPYC 7713 2.0GHz 64-core 225W Processor for HPE, 1TB RAM (16x64GB) Dual Rank x4 DDR4-3200 CAS-22-22-22, 24 X HPE 6.4TB SAS 24G Mixed Use SFF BC Multi Vendor SSD. The disks are capable of 4KB Random Read: 200000 IOPS and 4KB Random Write: 310000 IOPS.
Hey Tony,
It’s hard to do so, you can do it roughly by taking 30% of what the physical disk is capable of. You can use VMfleet to test the IOPS on the cluster when it’s online.
It would not recommend going the 16-node cluster route, you have the same amount of resiliency when doing 8 nodes.
Send me an email through contact if you need more info.
Thanks Darryl. We just need an approx number, so can we do (number of disks * Disk IOPS * Number of nodes)*30%.
I guess there could be some limitation on the node level performance also, but unable to get anything in server data sheets.