In the previous parts we’ve configured our network infrastructure with DCB and set QoS policies to ensure traffic bandwidth. But there is more!
In this part I’m going to shown known and unknown tips and tricks that optimizes your network infrastructure.
Part 1: RDMA, DCB, PFC, ETS, etc
Part 2: Configuring DCB in Windows
Part 3: Optimizing Network settings
Part 4: Test DCB and RDMA (coming)A
Jumbo Frames
Traditionally, Ethernet has a maximum frame size of 1500 bytes. An Ethernet packet larger than 1500 bytes is called a jumbo frame. When a network device gets a frame that is larger than the configured MTU, the data is fragmented into smaller frames or dropped. With jumbo frames, the ethernet packet can hold more data which makes data receiving more efficient as normally you would have to send 6 packets to transfer the same amount of data.
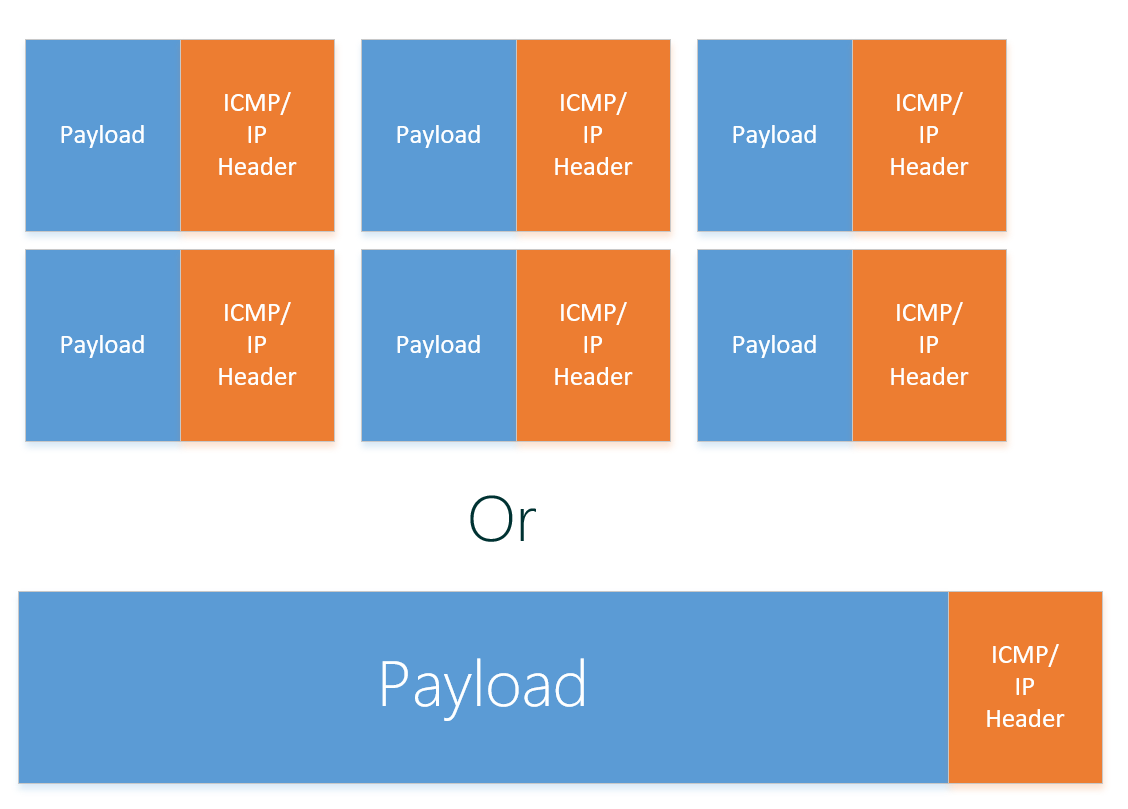
Jumbo Frames are always under debate, if it really makes a difference and need to be enabled.
I’m not going into research here, but see this blogpost for some performance tests.
http://longwhiteclouds.com/2013/09/10/the-great-jumbo-frames-debate/
In short, jumbo frames enhance IOPS and latency by 20-30% and decrease CPU usage.
I don’t see a reason not to enable it, which is fairly easy:
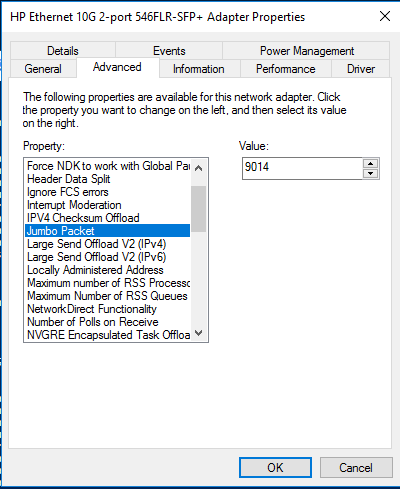
Our beloved Powershell can also do this for you:
Do not forget to enable jumbo frames on the switch as well.
You can test jumbo frames by sending jumbo frames:
The “-f” parameter does not allow packets to be fragmented.
The “-l” parameter specifies the size of the packet, in this case we use a large packet (jumbo frame).
If you get reply’s everything works great!
NUMA Node Assignment
(Text from Mellanox)
Non-uniform memory access (NUMA) nodes are servers with more than one system bus. These platforms can utilize multiple processors on a single motherboard, and all processors can access all the memory on the board. When a processor accesses memory that does not lie within its own node (remote memory), data must be transferred over the NUMA connection at a rate that is slower than it would be when accessing local memory. Thus, memory access times are not uniform and depend on the location (proximity) of the memory and the node from which it is accessed.
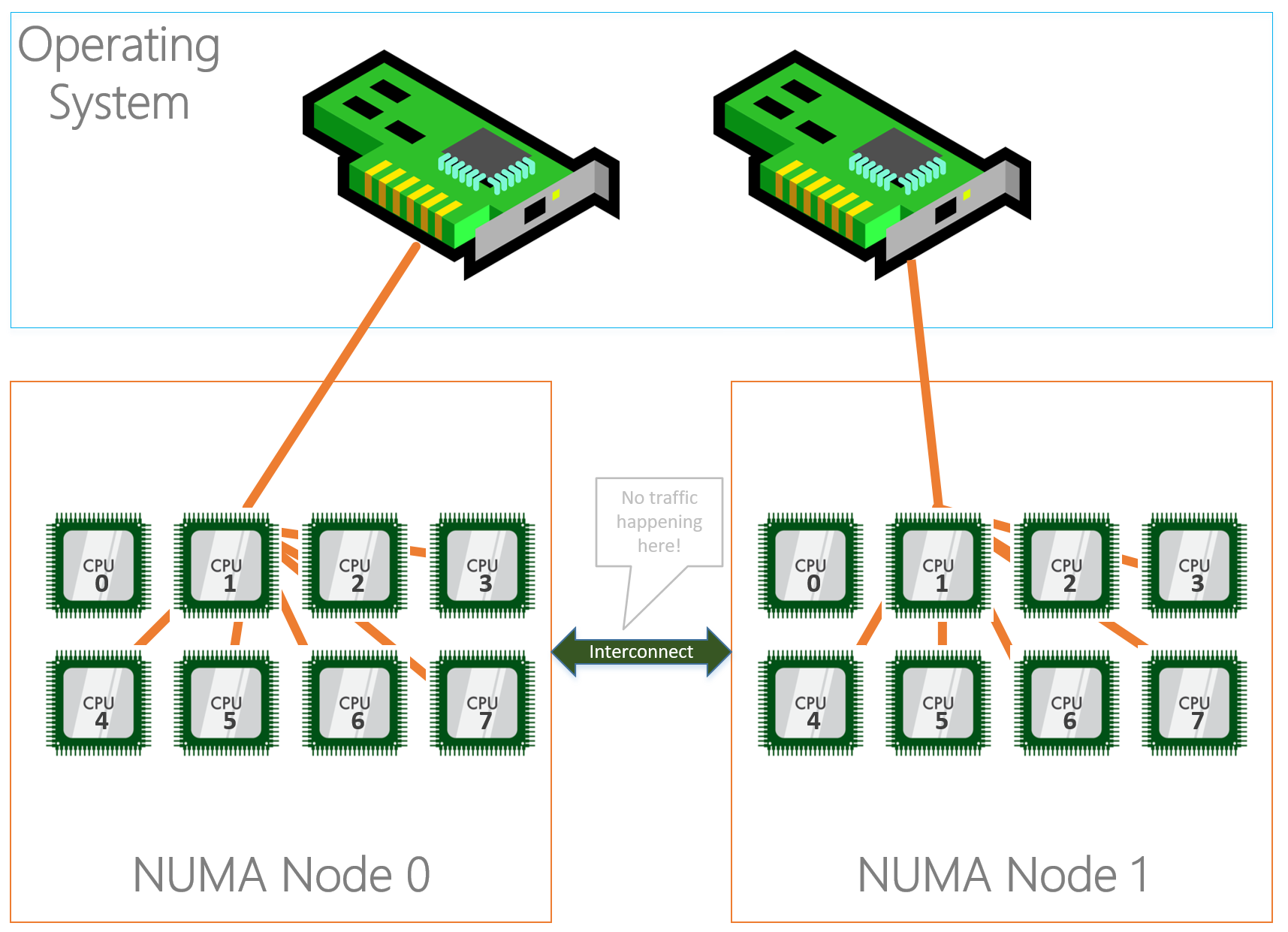
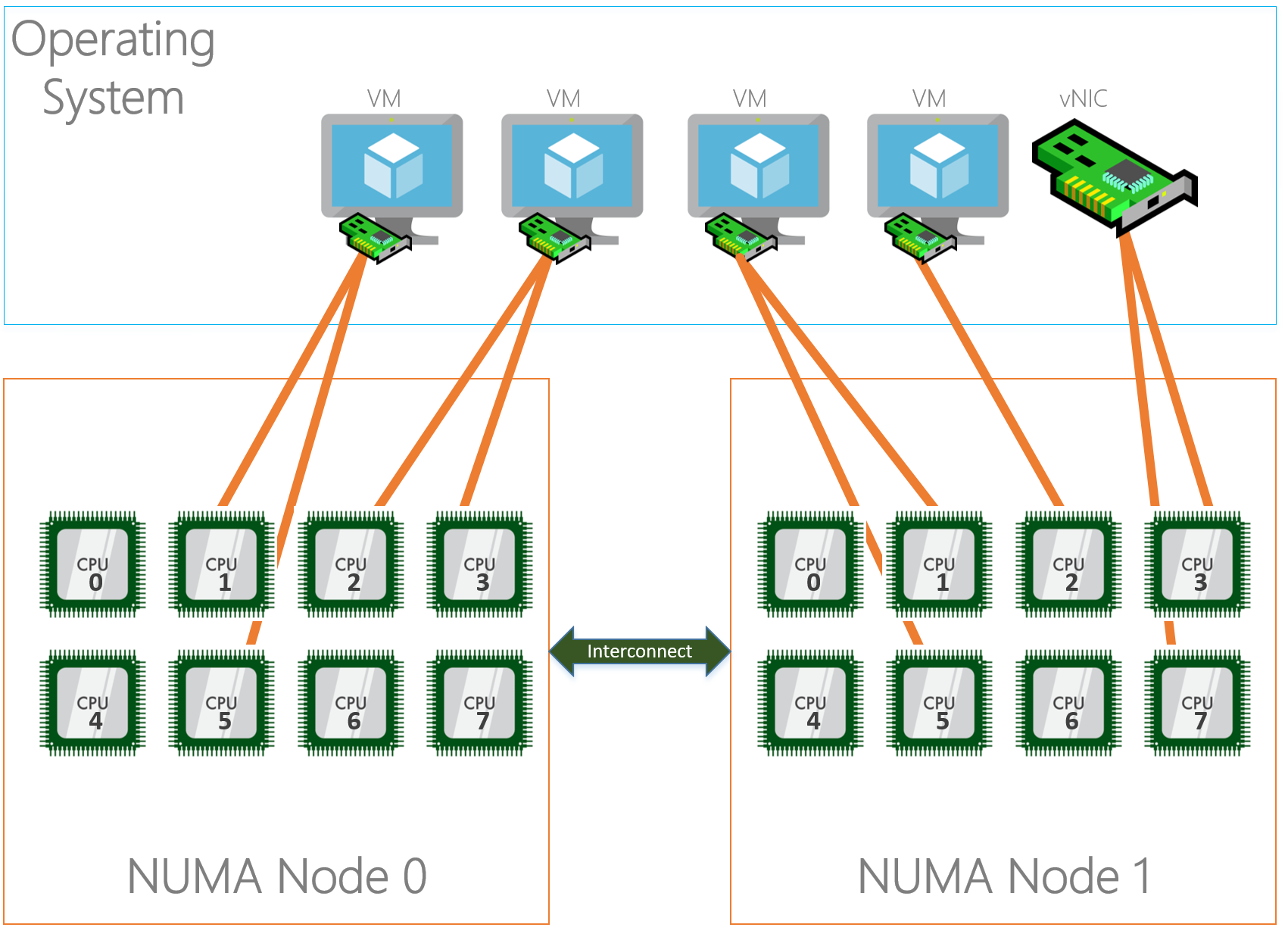
Basically what the above text describes is that a server’s hardware is fragmented in even pieces. Based on where the processor, memory and PCI slots is located on the motherboard its “assigned” to each other into a NUMA node. This way I/O is optimized and happens in the same “region” although I/O can cross NUMA nodes when needed, the latency will just be higher. Typically a NUMA node is formed on a physical processor socket, so if you have a two socket machine you would have two NUMA nodes.

To figure out how many NUMA nodes you have you could use the following Powershell cmdlet:
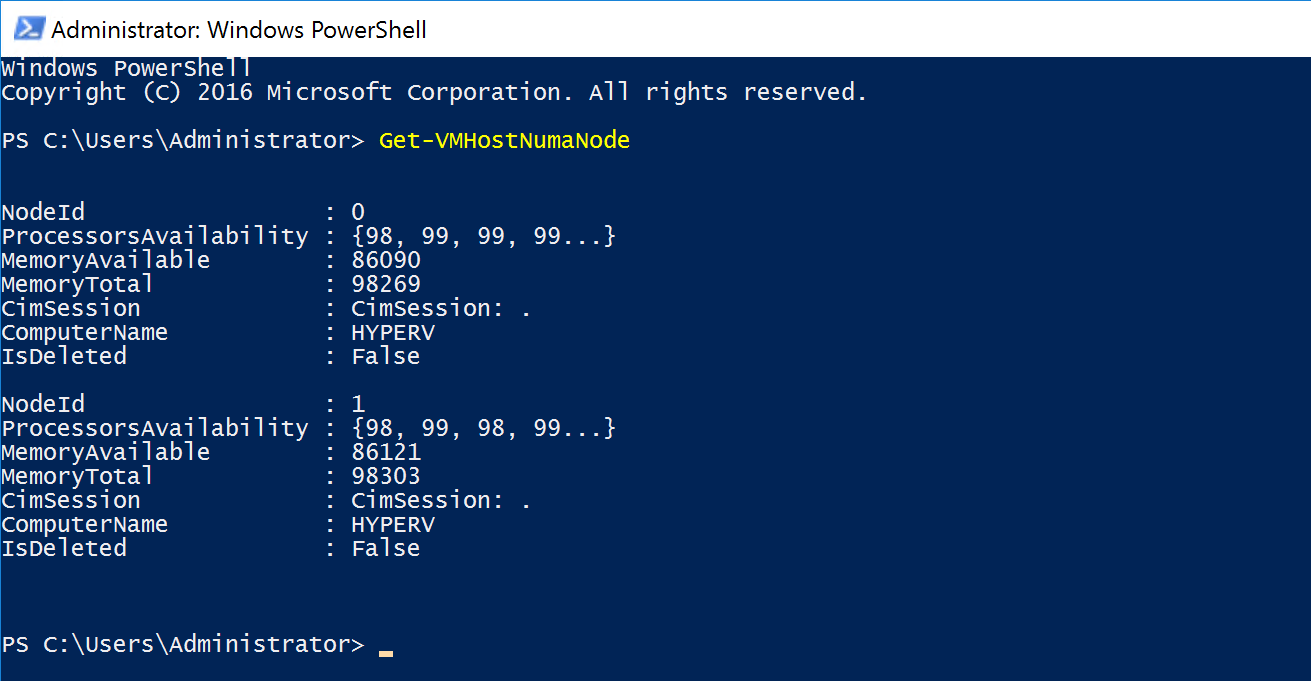
Physically the PCI-e slots are bound to a NUMA node, but that doesn’t mean that the NICs in the operating system are bound to the same NUMA nodes. By default all NICs seem to bind to NUMA node 0.
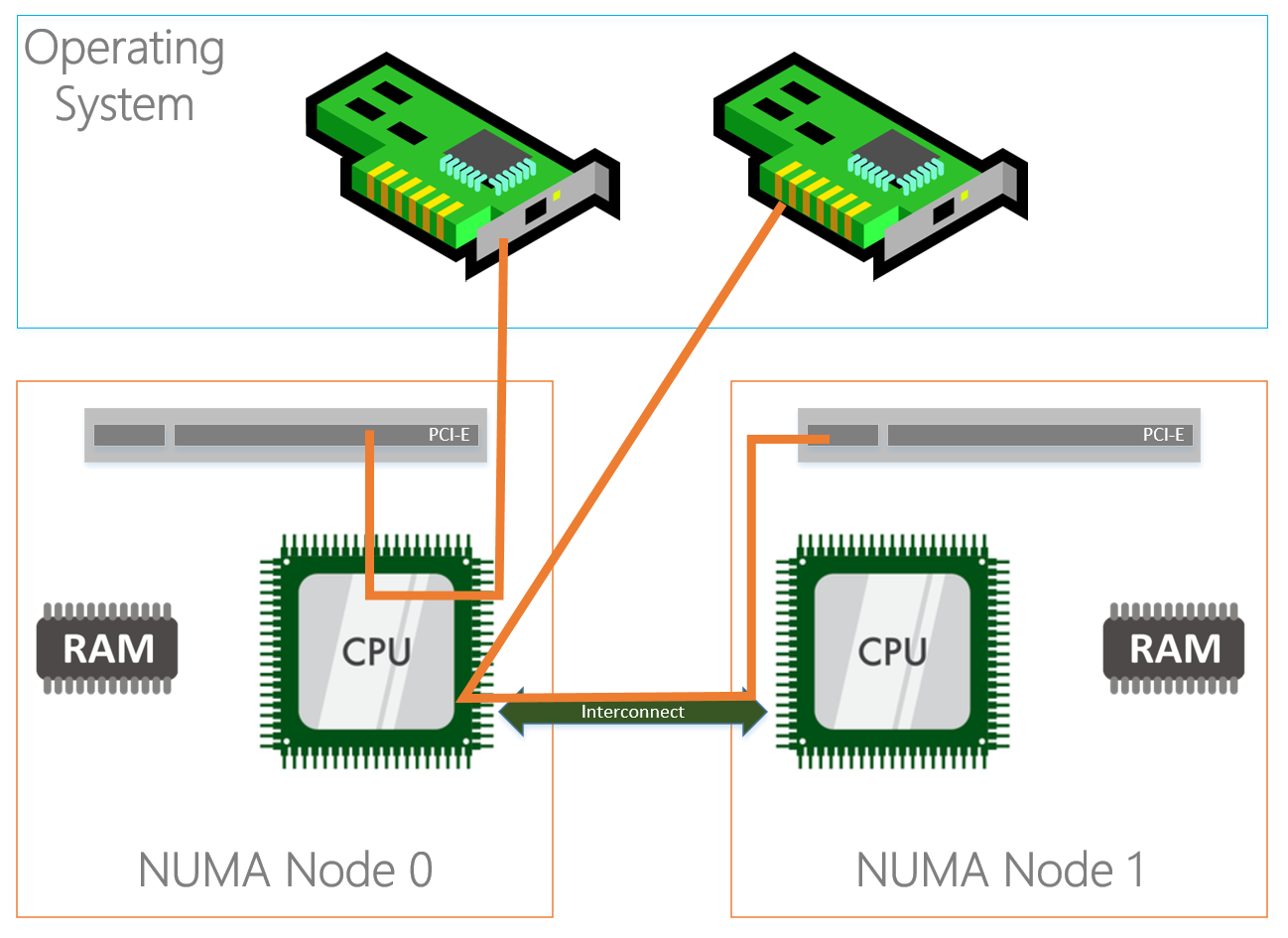
As you can see in the diagram above, the NIC (in the OS) on the left is physically installed in the PCI-e slot located in NUMA Node 0 and the CPU in the same NUMA node is processing I/O. The NIC on the right is physically located in NUMA Node 1 but the CPU in NUMA node 0 is processing I/O which is not optimal because both NICs are interrupting the same processor while we have another processor that can be used as well. On top of that the I/O’s also have to travel over the interconnect which causes latency.
You can view this latency by using the Get-NetadapterRss cmdlet:
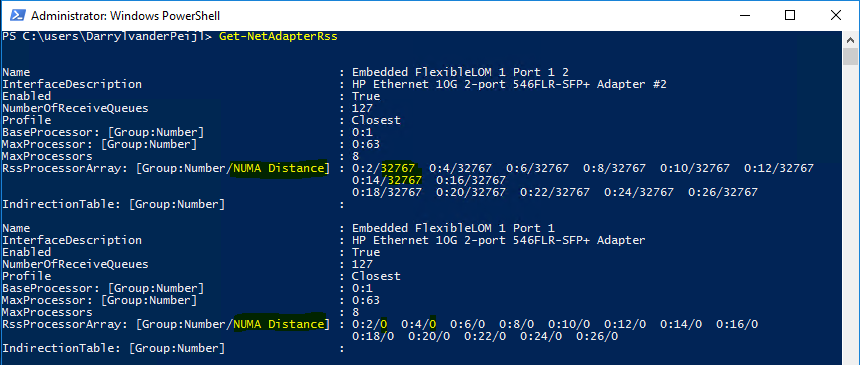
Modern NICs allow assigning to a specific NUMA node in the operating system which overcomes the situation outlined above. In the example below we used a Mellanox ConnectX-3 Pro adapter.

Set-NetAdapterAdvancedProperty -Name "NIC2" -RegistryKeyword '*NumaNodeId' -RegistryValue '1'
After changing the NUMA node assignment, you can see that the latency is reduced:
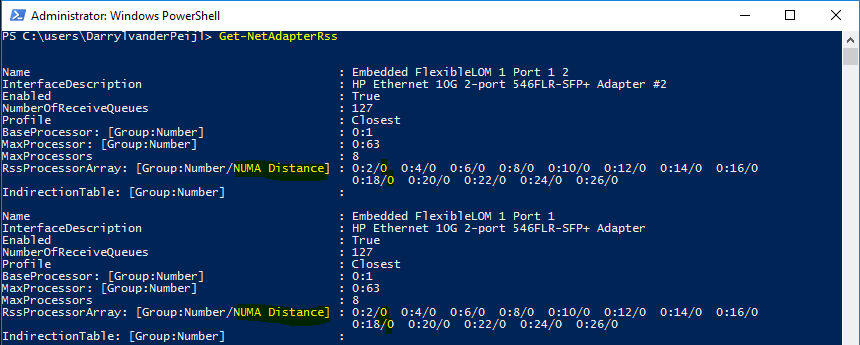
“But hey, SMB Direct (RDMA) doesn’t use the processor right?”
Correct, if you’re using RDMA your SMB traffic already bypasses the processor but it still applies for any other traffic (Including traffic of your virtual machines!). If you are not using RDMA this could help a lot.
Receive Side Scaling
Receive Side Scaling (RSS) is a very important aspect in networking on Windows. RSS makes sure that incoming network traffic is spread among the available processors in the server for processing. If we do not use RSS, network processing is bound to one processor which will limit approximately at 4GBps. Nowadays every NIC has RSS enabled by default, but the configuration is not optimized. Every NIC is configured with “Base Processor” 0, meaning it will start processing on processor 0 together with the others NICs but more importantly it’s the default processor for Windows processes as well.
To optimally configure RSS we want to start at processor 1 so we don’t interfere with processes landing default on processor 0. On the other hand, we also want to keep the NUMA node assignment as discussed above in mind so that RSS traffic is not using a processor in NUMA node 1 while the NIC is bound to NUMA node 2. This will have the same latency consequences as described above.
To configure RSS, for the physical NICs and the virtual NICs you can use the Set-NetAdapterRss cmdlet.
When you specify the “-NumaNode” parameter, it automatically changes the “Processorgroup” to the right number. We specify the “-BaseProcessorNumber” parameter to let RSS start on processor 1 instead of 0.
Set-NetAdapterRss -Name NIC2 -BaseProcessorNumber 1 -NumaNode 1
Set-NetAdapterRss -Name "vEthernet (SMB1)" -BaseProcessorNumber 1 -NumaNode 0
Set-NetAdapterRss -Name "vEthernet (SMB2)" -BaseProcessorNumber 1 -NumaNode 1
The examples assume we have an equal amount of NICs and NUMA nodes and uses all processors in a NUMA node for one NIC, but it could be that you have more NICs than NUMA nodes and you have to spread for example 4 NICs amongst two NUMA nodes. In this case you can specify a range of processors the NIC may use using the “-MaxProcessorNumber”, which specifies the fixed processor where the range ends from the “BaseProcessorNumber” or the “-MaxProcessors”, which is a count of how many processors it may use from the “BaseProcessorNumber”.
Examples to make it more clear:
This example uses processor 1 as start and the range stops at processor 6.
This example uses processor 8 as start and the range stops at processor 11.
Virtual Machine Queuing
With the entrance of virtualization on servers and RSS we hit some limitations because RSS wasn’t built for this “new world”. Long story short, when having a virtual switch on the system where physical adapters are bound to, RSS is disabled. This caused scalability issues that needed to be solved… hello VMQ.
(Text from VMQ Deepdive)
The real benefit of VMQ is realized when it comes time for the vSwitch to do the routing of the packets. When incoming packets are indicated from a queue on the NIC that has a VMQ associated with it, the vSwitch is able the direct hardware link to forward the packet to the right VM very very quickly – by passing the switches routing code. This reduces the CPU cost of the routing functionality and causes a measurable decrease in latency.
Unlike RSS where incoming traffic is spread among processors, VMQ will create a queue for each mac-address on the system and link that queue to a processor core. This means that a mac-address, which translates to a NIC of a VM or a host vNIC does not have more process power than 1 processor core. This limits the network traffic speed in the same way it does when we do not enable RSS to about 4GBps.
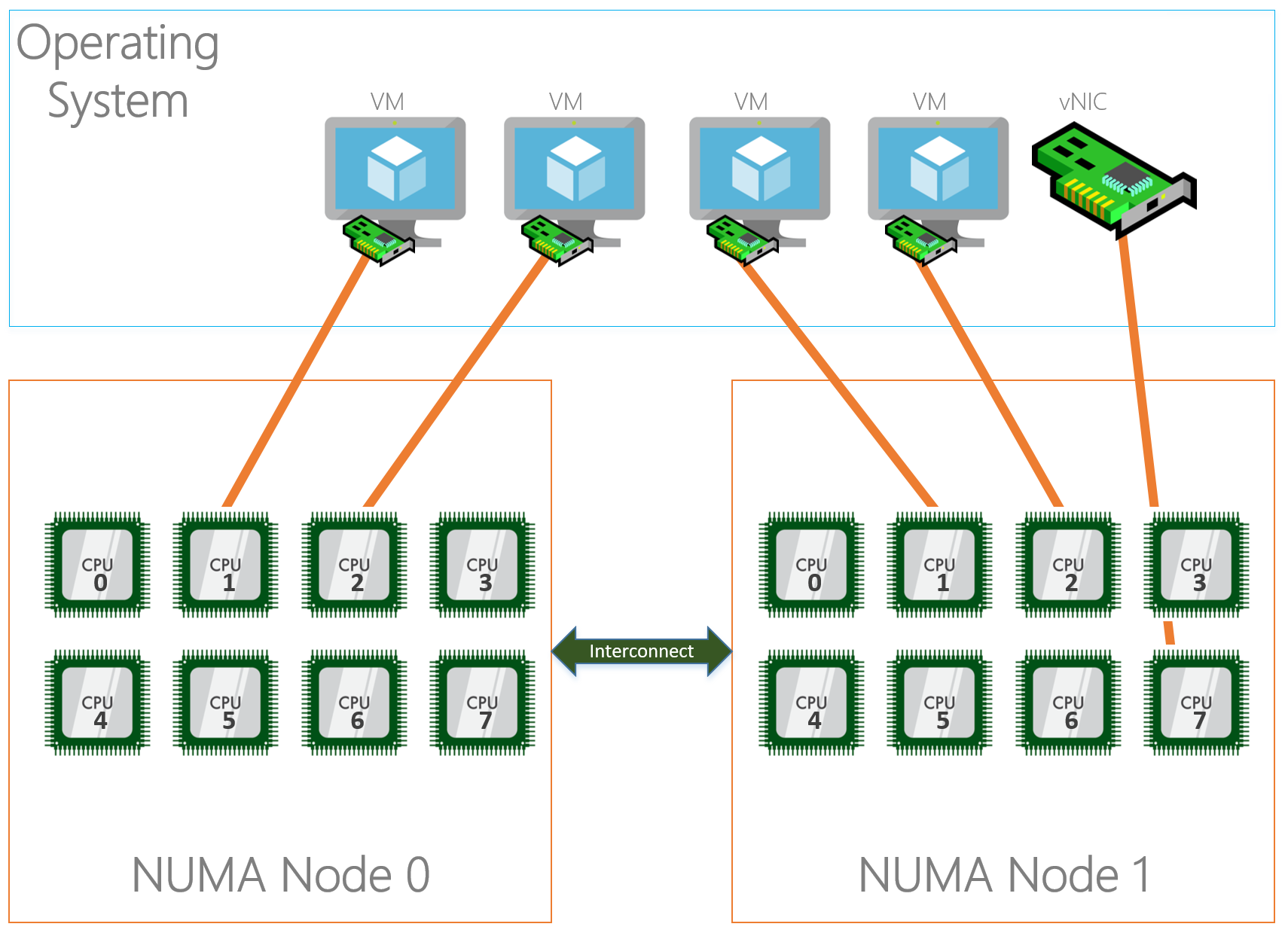
Some NICs have the capability to enable ‘dVMQ’ which stands for Dynamic VMQ. With this, queues can be reassigned to a different CPU at run time based on CPU load and system power balancing helping with a ‘noisy neighbor’.
When configuring RSS, VMQ follows this configuration. You can also manually configure VMQ using the “Set-NetAdapterVMQ” with the same parameters as the RSS cmdlet uses.
Virtual Machine Multi Queuing
New in Windows Server 2016 is a technology called VMMQ. The name doesn’t leave anything to a surprise, with Virtual Machine Multi Queuing multiple queues can be assigned to a VM NIC or Host vNIC. This helps us to get around the restriction of VMQ where we only have the ability to use one physical core per VM, if 4GBps of network traffic to your VM isn’t enough 🙂
VMMQ can be enabled using Powershell.
For a specific VM:
For a Host vNIC:
VM Network Team Mapping
After you have bound your physical NICs to a NUMA node, configured RSS and VMQ to use the right NUMA node and processors there is one more step to take.
By default an algorithm is in place to affinitize a vNIC to a Physical network adapter when they are in a team (LBFO or SET). This algorithm does not always do the things you want, If I have two storage NICs created on my vSwitch I would like them affinitized both on a different physical adapter.
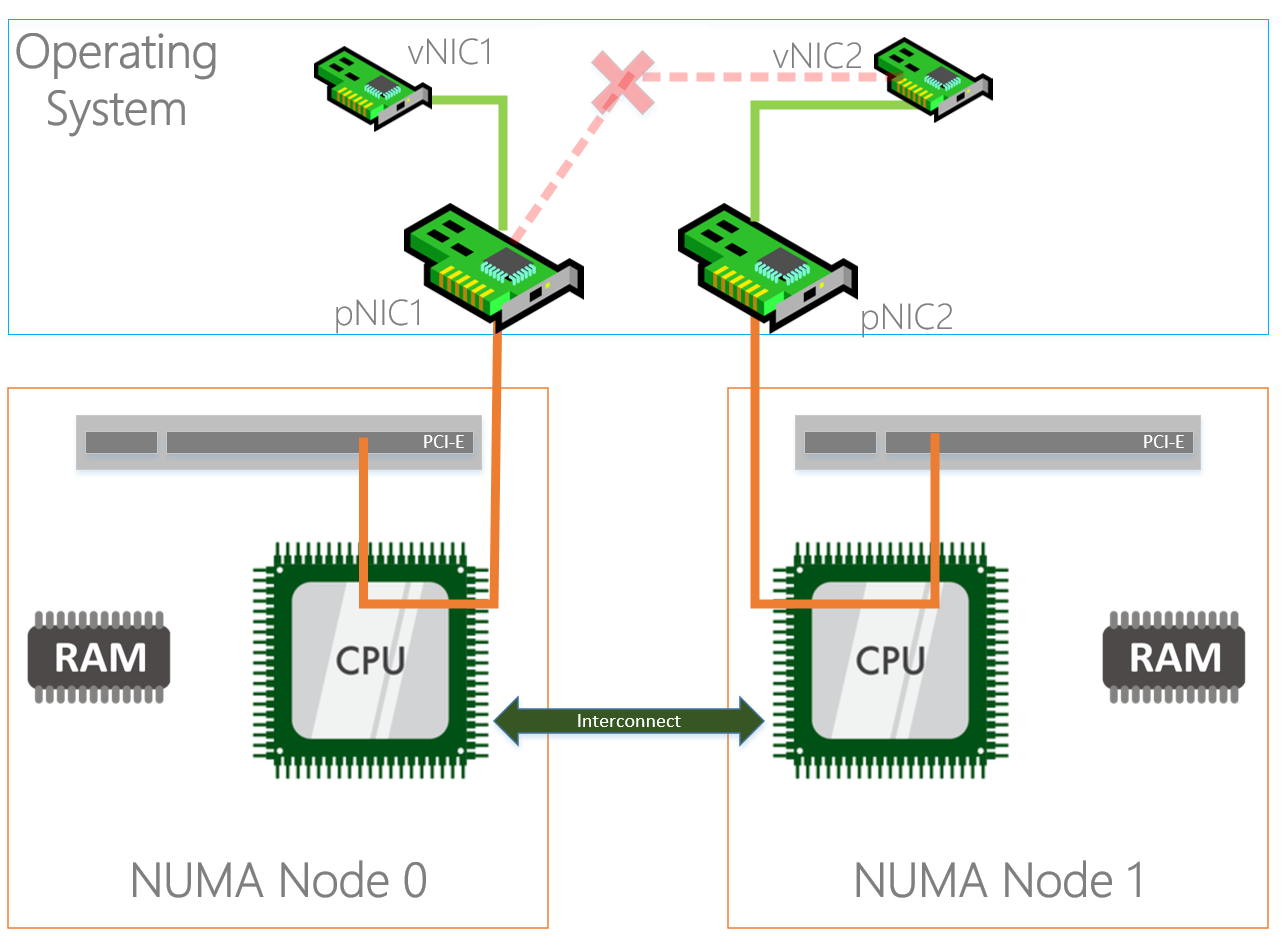
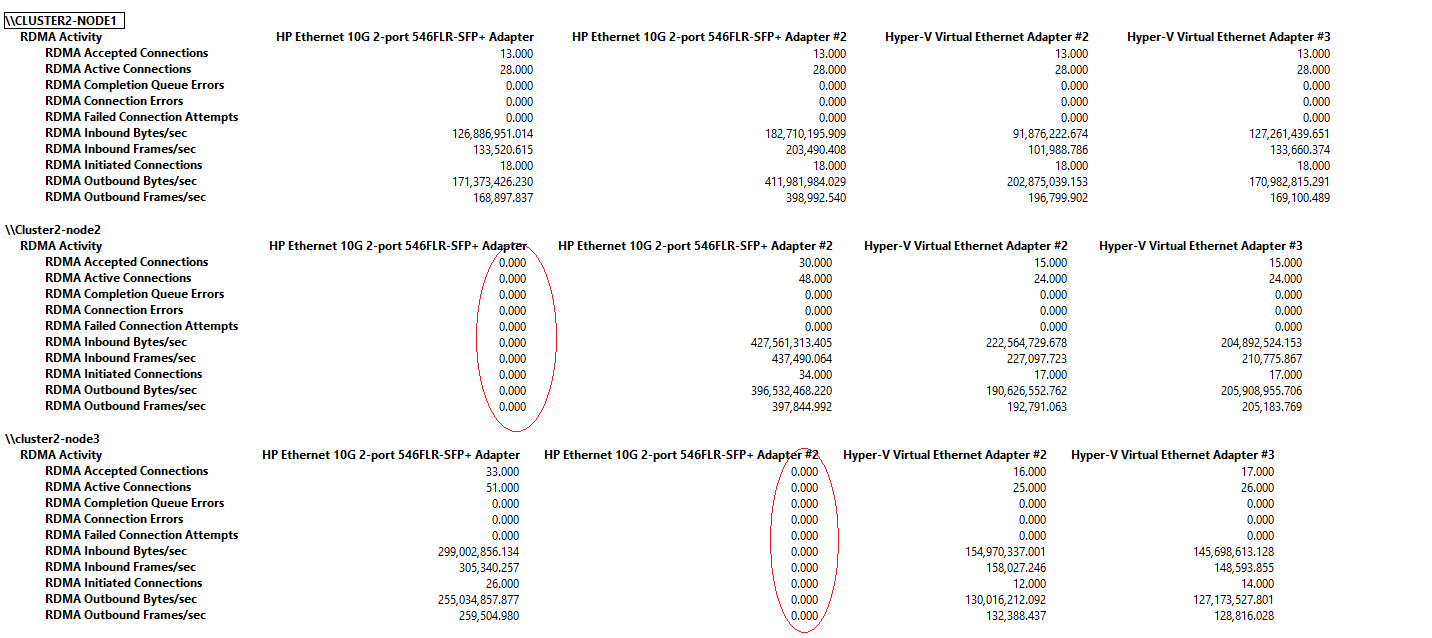
Below you will see an example of PerfMon where on “Cluster2-Node1” everything is affinitized properly but on the other two nodes you can see that one of the two physical adapters is doing no traffic at all. This is because both the vNICs are affinitized on one physical adapter.
You can affinitize a vNIC to a pNIC using the following Powershell cmdlets:
Set-VMNetworkAdapterTeamMapping -VMNetworkAdapterName SMB2 –ManagementOS –PhysicalNetAdapterName NIC2
With the above outlined settings and configurations you come along way optimizing your network environment on Windows Server 2016. If you follow the steps, all network related settings are aligned and optimized. Do not forget to test your environment.
—
Thank you for reading my blog.
If you have any questions or feedback, leave a comment or drop me an email.
Darryl van der Peijl
http://www.twitter.com/DarrylvdPeijl



Examples to make it more clear:
Set-NetAdapterRss -Name NIC1 -NumaNode 0 -BaseProcessorNumber 1 -MaxProcessorNumber 6
This example uses processor 1 as start and the range stops at processor 7.
Shouldn’t that be:
This example uses processor 1 as start and the range stops at processor 6.
Yup, it does 🙂
Thanks Alain!
Great blog 🙂 Question: What if I have one network card (using one PCIe slot) with 2 x ports? Then I guess both physical ports should be assigned to Numa Node 0? or?
Hi Rene,
It depends to which NUMA node the PCIe slot is bound..
Could be that its bound to NUMA node 1, you can check the distance with the Get-NetAdapterRSS cmdlet as shown in the blog, this way you know for sure.
I have a question about using Set-VMNetworkAdapterTeamMapping to affinitize vNICs to a Physical NIC. My configuration is using 2 Mellanox Dual port adapters. So I have 4 physical nics. I found out that you can only have 1 vNIC per Physical NIC. With this configuration would you have SMB1 going to Slot 2 Port 1 and SMB2 going to Slot 3 Port 1?
Hi Kris,
Yes that’s something I would do as well.
Hi Darryl,
Brilliant article, thank you!
Hello Darryls!
Thanks you for the great post. But Can you see what is a good value for de other vNetworks in a hyper-converged infrastructrure with Livemigration, ManagementOS and ClusterHearbeat and SMB1+SMB2 vEthernets?
Of Course we will set the both SMB vEthernet to easy Core per Node, but what about the other vEthernets like Livemiration, Clusterhearbeat and Management?
Thank you for you answer in advanced.
Hi Sinan,
In the new converged setup with 2016 I actually never deploy dedicated Live migration and Cluster heartbeat networks anymore.
Both are using the SMB/Storage networks. As long if you configure your QoS the right way, this should not be an issue.
Hello Darryl
Thank you for your quickly answer!
Yes it was also a option to do everything to the SMB Network. But now we decided and built it in classical way to get the “better” support from MS.
We will actually do 2 physical NIC (in SET) with 5 vEtherner for S2D Hyper-V Cluster. –> VEthernet= SMB1,SMB2,ClusterLM,ClusterHB & Management.
We have for each nodes 2x 14Core CPU. Can you help me in my configuration or can you give me a feedback? Woult be very great from you.
1. Physical Interface: BaseProcessorNumber 1 -NumaNode 0
2. Phsyical Interface: BaseProcessorNumber 15 -NumeNode 1
1. Virtual SMB Interface: BaseProcessorNumber 1 -NumaNode 0
2. Virtual SMB Interface: BaseProcessorNumber 15 -NumeNode 1
Virtual LiveMigration Interface: BaseProcessorNumber 1 -MaxProcessorNumber 3
Virtual ClusterHB Interface: BaseProcessorNumber 5 -MaxProcessorNumber 3
Virtual Management Interface: BaseProcessorNumber 15 -MaxProcessorNumber 3
–> We will only do and configure RSS (vRSS).
What about VMQ? Schould we do something? Our VM’s will bind the SET Switch in Hyper-V. Shoul we do a Config for VMQ in our szenario?
Hi Sinan,
The “BaseProcessorNumber” is bound to the NUMA node, so for both NUMA nodes you start at “-BaseProcessorNumber 1”
If you want to have dedicated cores for LM and Cluster, you will have to limit the physical and SMB interfaces with “-MaxProcessorNumber” and then assign those cores to LM and Cluster.
Please keep in mind that with RDMA adapters, not much RSS will be used (hopefully).
Hey Darryl!
Perfekt then i will do a simple way for this affinity:
On the SMB Adapter and physical Adapter
1.SMB & 1. Physical: -BaseProcessorNumber 1 -NumaNode 0
1.SMB & 1. Physical: -BaseProcessorNumber 1 -NumaNode 1
For all other VEthernets i will do just: -BaseProcessorNumber 1 to prevent de Core 0 from the “first” CPU.
Hi Derryl.
I did these two lines for my Hyper-V hosts with 8 and 10 cores – can you comment if this is done correctly?
8 CORES :
Set-NetAdapterVmq -Name “Production Member 1” -BaseProcessorNumber 4 -MaxProcessorNumber 14 -MaxProcessors 6
Set-NetAdapterVmq -Name “Production Member 2” -BaseProcessorNumber 20 -MaxProcessorNumber 30 -MaxProcessors 6
10 CORES :
Set-NetAdapterVmq -Name “Embedded FlexibleLOM 1 Port 1” -BaseProcessorNumber 2 -MaxProcessorNumber 18 -MaxProcessors 9
Set-NetAdapterVmq -Name “Embedded FlexibleLOM 1 Port 2” -BaseProcessorNumber 22 -MaxProcessorNumber 38 -MaxProcessors 9
Appreciated! 🙂
Correction – no way to edit my comment? 🙂
8 CORES :
Set-NetAdapterVmq -Name “Embedded FlexibleLOM 1 Port 1” -BaseProcessorNumber 2 -MaxProcessorNumber 14 -MaxProcessors 7
Set-NetAdapterVmq -Name “Embedded FlexibleLOM 1 Port 2” -BaseProcessorNumber 18 -MaxProcessorNumber 30 -MaxProcessors 7
10 CORES :
Set-NetAdapterVmq -Name “Embedded FlexibleLOM 1 Port 1” -BaseProcessorNumber 2 -MaxProcessorNumber 18 -MaxProcessors 9
Set-NetAdapterVmq -Name “Embedded FlexibleLOM 1 Port 2” -BaseProcessorNumber 22 -MaxProcessorNumber 38 -MaxProcessors 9
Why would you specify “-MaxProcessorNumber” and “-MaxProcessors”, you can use either of the two to accomplish the same.
In other words, you can remove “MaxProcessors” and it should work 🙂
The best way to test is push enough network traffic so you can see which cores are used.
Good luck!
I see – thank you 🙂
However we do see a trend with vRSS and VMQ.
I get these events often on my 2016 Hyper-V hosts :
Memory allocated for packets in a vRss queue (on CPU 24) on switch 2F575A63-1D84-4B62-A1E0-1BCCE111448B (Friendly Name: Data Virtual Network) due to low resource on the physical NIC has increased to 512MB. Packets will be dropped once queue size reaches 512MB.
Why am I getting these errors?
Hello. I am just trying to enable Jumbo Frames and having some issues and questions perhaps you can answer. Also on Server 2016 here.
I set Jumbo Frames on my physical interfaces 10gbps interfaces to 9014 as per the instructions here. These two interfaces back a virtual switch, in particular iSCSI interfaces called vEthernet (Storage). I set the vEthernet (Storage) interface to jumbo frames as well (I believe I am supposed to, found info online) with this command netsh interface ip set subinterface “vEthernet (Storage)” MTU=9000 STORE=PERSISTENT
However, doing the ping with large packets results in a “Request Timed out”. I am planning on driving the iSCSI traffic (for Hyper-V host storage) right through the vSwitch, and I believe this should work. Any advice?
Hi Dmitiri,
This should work indeed.
You can use this Powershell cmdlet for your vNICs:
Set-NetAdapterAdvancedProperty -Name ‘vEthernet (NICNAME)’ -RegistryKeyword ‘*JumboPacket’ -RegistryValue ‘9014’
Dont forget that your physical switch also needs to have jumbo frames enabled if you want to let the packets outside of your cluster.
hello. Thank you for such a informative and detailed article. I have a question concerning how you “Affinitize” the vNic to pNICs as follows:
Set-VMNetworkAdapterTeamMapping -VMNetworkAdapterName SMB1 –ManagementOS –PhysicalNetAdapterName NIC1
Set-VMNetworkAdapterTeamMapping -VMNetworkAdapterName SMB2 –ManagementOS –PhysicalNetAdapterName NIC2
I understand the binding of the virtual interface to the Physical interface. What I don’t understand is how it functions. In other words, if one vInterface if 192.168.0.1/24 and the other is 192.168.0.2/24, how will communication use both interfaces? If another host in the cluster needs to communicate with any other host, I assume it will perform a look up and will be given one of the two ip addresses correct? If so, would communication use said IP and ignore the other? Am I missing something?
Thanks again for the great article.
Hi Victor,
I hope I understand correctly. The SMB Client are using SMB Multichannel to communicate over both NICs.
See this for more info: https://blogs.technet.microsoft.com/josebda/2012/06/28/the-basics-of-smb-multichannel-a-feature-of-windows-server-2012-and-smb-3-0/
I use RSS and VMQ across a dual processor, 16 core E5 (32 HT). Does this look right as I’m still getting issues. Love your site by the way!
Set-NetAdapterRss -interfacedescription “HPE Ethernet 25Gb 2-port 640SFP28 Adapter” –BaseProcessorNumber 0 –MaxProcessors 8
Set-NetAdapterRss -interfacedescription “HPE Ethernet 25Gb 2-port 640SFP28 Adapter #2” –BaseProcessorNumber 16 –Maxprocessors 8
Set-NetAdapterVmq -interfacedescription “HPE Ethernet 25Gb 2-port 640SFP28 Adapter” -BaseProcessorNumber 32 -MaxProcessors 8
Set-NetAdapterVmq -interfacedescription “HPE Ethernet 25Gb 2-port 640SFP28 Adapter #2” -BaseProcessorNumber 48 –MaxProcessors 8
*cant edit comments…….I have 2x E5 2620 v4 so 8 real cores. 16 HT = 16 real cores. I think I’ve miss calculated my rss\vmq
Let me know if you still need help 🙂
Hi,
I have two processor sockets/server and each with 18 cores and I have multiple networks setup on dual port 40gig converged mellanox NIC. I have tried to do the RSS and vmq as explained above and I have been having issues when i setup as per your guide lines here. First of all, setting a numanode does not change the group, at least for me, so the way i managed to do it is as shown below
with hyper threading enabled, 18 cores /socket, gives 36 cores and 72 logical cpus. I have 7 networks on converged nics assigned to SET vswitch. The networks are Management,LM,Cluster,Management,SMB1,SMB2. Can someone please take a look and let me know if this is OK?
Set-NetAdapterrss -Name “vEthernet (SMB1)” -NumaNode 0 -BaseProcessorNumber 18 -MaxProcessorNumber 32 -BaseProcessorGroup 0
Set-NetAdapterrss -Name “vEthernet (SMB2)” -NumaNode 1 -BaseProcessorNumber 18 -MaxProcessorNumber 32 -BaseProcessorGroup 1
Set-NetAdapterRss -Name NIC1 -BaseProcessorNumber 2 -NumaNode 0 -MaxProcessors 8 -MaxProcessorNumber 16 -BaseProcessorGroup 0
Set-NetAdapterRss -Name NIC2 -BaseProcessorNumber 2 -NumaNode 1 -MaxProcessors 8 -MaxProcessorNumber 16 -BaseProcessorGroup 1
Set-NetAdapterVmq -Name “NIC1” -NumaNode 0 -BaseProcessorNumber 2 -MaxProcessors 8
Set-NetAdapterVmq -Name “NIC2” -NumaNode 1 -BaseProcessorNumber 2 -MaxProcessors 8
Set-NetAdapterrss -Name “vEthernet (LM)” -NumaNode 1 -BaseProcessorNumber 34 -BaseProcessorGroup 1
Also setting VMMQ as shown below crashing windows.
Set-VMNetworkAdapter -name “SMB1” -ManagementOS -VMMQEnabled $True
Set-VMNetworkAdapter -name “SMB2” -ManagementOS -VMMQEnabled $True
Set-VMNetworkAdapter -name “LM” -ManagementOS -VMMQEnabled $True
Hi Darryl,
I didn’t understand the VMMQ part. By configuring VMMQ, aren’t we supposed to bind a vNIC to a core or not? If yes, how is this accomplished? By enabling the VMMQ, a vNIC is automically bound to a core?
Thank you very much for your reply!
You can still specify which range of cores VMQ may use, and then VMMQ will spread among that range.
Hope it helps,
Darryl
Hi Darryl,
Thanks for your great article, still struggling a bit with all the settings you can choose but the main question I have is as follows;
We have HP BL460c Gen 9 with HP FlexFabric 20 GB 2-port 650FLB adapters and we are testing/configuring to use them in 2016 HyperV clusters. I was wondering if there is a way to see if both NIC’s (Emulex) are actually attached to seperate cpu’s (Numa nodes). We believe that only one PCIe slot is used for both LOM’s, so they would only be physically attached to one NUMA Node.
Does this eventually mean that we can only use one NUMA node for all RSS setting without a latency penalty?
Or do we first need to set the Preferred NUMA node setting before we can use it. Which would mean that we need to be certain that both NIC’s have there own NUMA node.
Hope to hear from you
Peter
Hi Peter,
We believe that only one PCIe slot is used for both LOM’s, so they would only be physically attached to one NUMA Node.
I think so as well.
Does this eventually mean that we can only use one NUMA node for all RSS setting without a latency penalty?
You need to figure out if both LOM’s are connected to the same NUMA nodes and what the latencies are as shown in the blog.
very good blog cheers for posting this
Hi Darryl
Thanks for this amazing article!
One thing that puzzles me though..
From your NUMA Node Assignment example I understand you got a 546FLR-SFP+ Dual Port pNIC, which means both ports are either bound to NUMA Node 1 or NUMA Node 2 right?
I don’t get how you can reduce the NUMA Distance by assigning one port on the same NIC to the NUMA Node it doesn’t actually belong to? Am I missing something here?
Regards,
Manuel
Hi Manuel, very good question 😉
I looked into this when creating this blog post as it had me puzzled as well. And if I remember correctly, HPE (Gen9 in this case) does something with the assignment of the PCIe devices as they are not specifically fixed bound to a specific CPU. The bios sees two devices on the PCIe bus and assigns them among NUMA nodes. Very limited info on this behaviour..
Hi!
I am experimenting (RSS but I guess comparable to VMQ) on older HW with 2x4GbE nic’s (DL380Gen8 2xCPU). Each CPU has it’s own PCI riser card so one 4portsNIC Per CPU. Each CPU has 4 cores, no Hyperthreading so 8 cores for RSS (Windows Server 2019)
Out of the box Windows assigns all cores to all adapters like this command;
Set-NetAdapterRss -Name “*” -BaseProcessorNumber 0 -MaxProcessorNumber 7 -MaxProcessors 8
But because each CPU has it’s own PCI bus with it’s own connected 4x1GbE Ethternet card supposedly this would be better;
CPU0 -> Core0 to 3 assigned to local PCI Ethernet adapter
Set-NetAdapterRss -Name “NIC-NUMA-Node0*” -BaseProcessorNumber 0 -MaxProcessorNumber 3
CPU1 -> Core4 to 7 assigned to local PCI Ethernet adapter
Set-NetAdapterRss -Name “NIC-NUMA-Node1*” -BaseProcessorNumber 4 -MaxProcessorNumber 7
So there is no QPI bus overlapping now, all PCI slots / cores are local.
So for now a good theory, but are there really negative impacts if you keep assigning CPU0/1 thru the QPI bus to each it’s PCI bus?
And if so, is it (always) advisable to (for HPE) buy an extra riser card for usage of the 2nd CPU PCI slots because it’s local to balance the RSS/VMQ cores?
Thanks!
Hi Arian,
It all depends on the hardware and what they support. It could happen that you assigned “NIC-NUMA-Node1*” to core 4-7 but the driver does not expose the ability to configure the NUMA node. Some vendors start counting at core0 per numa node, other do not. It is really about testing your system and hardware to figure this out.
Great Post!!!! I am gaining an understanding of RSS & NUMA and this took my understanding to another level….
SO, ignorant question…What does RSS do in a UMA architecture, a single bus with all the RAM attached and multiple processors on the single bus?
does it work at all? can RSS on a UMA architecture be configured to multi-process the NIC interrupts/DPCalls?
if so, how does one set the affinity to use a specific set of processors?
Never touched it. But I would suspect the same as NUMA. Tell me when you know 😉
Hello Darryl,
On server 2016 we are hitting eventid 113: Failed to allocate VMQ for NIC – Reason – Maximum number of VMQs supported on the Protocol NIC is exceeded. We have more vm’s running then queues available. This causes issues with several vm’s.
In this case can we safely disable vmq on the physical adapters using disable-netadaptervmq or will that have a performance impact ? Or do we need to either reduce number of vm’s or increase number of physical nics ?
The vm’s don’t require high bandwidth connections.
Best regards,
Jaco
Hoi Jaco,
There should be no issues when you run out of queues, an VM that has no queue assigned should not be an issue.
From top of my head, the algorithm gives the VMs that require the most bandwidth a queue.
If you disable VMQ on the physical NIC you could have impact on performance.
You can disable VMQ on VM level and only give the high performance VMs access to VMQ.
Regards,
Darryl
Different but related (Jumbo Frames) topic: NIC Teaming. I have 4 x 1Gbe Intel NIC’s in my home 2016 server (No Virtualisation). They are configured as a team-LACP to a Cisco SG300 switch LAG Group with Jumbo Frames enabled. The only option I can find is to set each physical NIC to Jumbo Packet exactly as you show at the every start of your article. There is no option within the “TEAM NIC” to set Jumbo Frames. However pings -f – l 8000 to anything else including the switch itself results in:
“Packet needs to be fragmented but DF set.” with total loss of packets
Ok to answer my own question – the TEAM NIC needs to be restarted AFTER setting each physical interface – and then pings fine!
Restart-NetAdapter “TeamName”
Thank you Darryl for a great article! Few questions —
1) If we enable VMMQ, do we need to worry about VMQ configuration? In other words is there a way to/should we exclude CPU0 from being utilized, as well as provide “BaseProcessorNumber–MaxProcessorNumber” boundaries for vNICs with VMMQ enabled?
2) You mentioned that RSS is disabled as soon as vSwitch is created, but under RSS section you show an example with RSS configuration on a vEthernet interface. Does it mean that you can turn RSS on for vNICs? How and when should we do it?
3) You mentioned that “When configuring RSS, VMQ follows this configuration.”. But as I understood it, RSS lets you assign a NIC to a range of CPUs, which VMQ can’t do by design – only one CPU is assigned. How is RSS configuration followed by VMQ then?
Sorry, trying to wrap my head around the big picture. Last, but not least –
4) If I understand it correctly: we assign physical NICS to NUMA nodes, while VMQ is configured on vNICs. If physical NIC0 is assigned to NUMA#0 while vNIC-A is “VMQed” to CPU1-4 on the neighbor NUMA#1, then we must exert extreme caution when mapping vNIC-A to the physical NIC. If we map it to NIC0 we will end up with sub-optimal configuration. Correct?
Thanks!
Hi Max,
Great questions!
1) It depends what OS you’re running on. With 2019 we’ve got Dynamic VMMQ where you do not have to worry about it. See https://techcommunity.microsoft.com/t5/Networking-Blog/Synthetic-Accelerations-in-a-Nutshell-Windows-Server-2019/ba-p/653976 for more info.
2) That is correct. RSS can be enabled to that you can use vRSS within the VM
3) You are mixing assignment of VMQ adapters to logical processors with VMQ queues assignments to logical processors.
F.e. you can do something like: Set-NetAdapterVMQ -Name NIC1 -NumaNode 0 -BaseProcessorNumber 1 -MaxProcessorNumber 6
But when a VM is deployed and its vNIC gets assigned to a VMQ queue, that queue is bound to a specific CPU.
4) Yes, but the impact will probably be minimal on VM traffic, unless it’s a high bandwidth VM needing low latency.
Hello,
we want to switch over to 10GB-E network. We are using the following hardware:
Hyper-V 2012R2 Cluster: 2x PE730, Sockets: 2, Cores: 20, LP: 40, NIC: 2x Intel X550-2Port (driver 3.14.115.1, fw 19.0.12 )
Switch: Dell EMC S4128T
Storage: Dell PV MD3420 direct attached, sas
To be able to use the “full bandwith” of the 10Gb LAN I want to setup RSS and VMQ. I decided to setup two switch independent dynamic teams. LAN (first X550) and HYPERV (vswitch – second X550). I am not sure what to setup in the nics and the team nic regarding vmq and rss.
My idea:
Team LAN: enable rss, disable vmq, leave rss/vmq enabled on team nic multiplexor.
Set-NetAdapterRss -Name “nic1port1” -BaseProcessorNumber 2 -MaxProcessorNumber 18 -MaxProcessors 8 -NumaNode 0
Set-NetAdapterRss -Name “nic1port2” -BaseProcessorNumber 22 -MaxProcessorNumber 38 -MaxProcessors 8 NumaNode 1
Team HYPERV: enable vmq, disable rss, leave rss/vmq enabled on team nic multiplexor.
Set-NetAdapterVmq -Name “nic2port1” -BaseProcessorNumber 2 -MaxProcessorNumber 18 -MaxProcessors 8 NumaNode 0
Set-NetAdapterVmq -Name “nic2port2” -BaseProcessorNumber 22 -MaxProcessorNumber 38 -MaxProcessors 8 NumaNode 1
Does this fit or is something totally nonsense? Enable srv-io?
Thanks in advance
Jay
Hi Jay,
You should RSS enabled on both cases. The rest seems to make sense.
Does any of this matter if you are only using a single 10Gb card, so no teaming?
It does matter for redundancy 🙂
Hi Darryl,
I meant does a 2016 Hyper-V host with a single 10Gb dual port network card benefit by setting the network card to a specific processor in a numa node and RSS make a difference if its not in a team?